
Анти капча сервис. Распознавание, решение и авто обход reCaptcha, hCaptcha, FunCaptcha Arkose Labs
- Цена от 44,00 ₽ за 1000 обходов капч
- Простой API
- Скорость до 12 сек
Сервис предназначен для автоматизации обхода капч. ruCaptcha может решать любые капчи по низкой цене.
Капчи распознаются работниками, поэтому сервис позволяет решать любые типы капч, которые способен решить человек.
Сервис полностью автоматизирован.
Никакого риска: оплата только за автоматически решенные капчи.
Быстрый старт
Как распознать капчу
Вы загружаете капчу на rucaptcha.com/in.php
Сервер сохраняет капчу и возвращает Вам ID капчи
Сервер незамедлительно передаёт капчу работнику
Работник решает капчу и отправляет на сервер ответ
Вы обращаетесь к серверу по ранее выданному ID и забираете ответ
Обход любой капчи
reCAPTCHA V2
- 65,00 ₽ — 160,00 ₽
- Цена за 1000
- 0 сек.

- Скорость решения

Процесс решения reCAPTCHA V2 заключается в следующем: мы забираем параметры капчи, необходимые для ее решения в виде параметра data-sitekey и адреса страницы размещения капчи и передаем их в сервис ruCaptcha, где ее решает работник, после чего нам возвращается ответ в виде токена, который необходимо ввести в соответствующее поле для решения капчи
API демоПримеры кода
Быстрый стартhCaptcha
- 160,00 ₽
- Цена за 1000
- 0 сек.
- Скорость решения
Процесс решения заключается в следующем: мы забираем параметры капчи, необходимые для ее решения в виде параметра data-sitekey и адреса страницы размещения капчи ruCaptcha и передаем их в сервис ruCaptcha, где ее решает работник, после чего нам возвращается ответ в виде токена, который необходимо ввести в соответствующее поле для решения капчи
API демоПримеры кода
Быстрый стартreCAPTCHA V3
- 99,00 ₽ — 160,00 ₽
- Цена за 1000
- 0 сек.
- Скорость решения

Процесс решения reCAPTCHA V3 следующий: мы забираем параметры капчи, необходимые для ее решения в виде параметра data-sitekey, параметра action и адреса страницы размещения капчи и передаем их в сервис ruCaptcha, где ее решает работник с соответствующим рейтингом «человечности”, после чего нам возвращается ответ в виде токена, который необходимо ввести в соответствующее поле для решения капчи. Во многом новый вид капчи похож на reCAPTCHA V2, т.е. основной принцип остался тем же — пользователь получает от API ruCaptcha токен, который отправляется в POST-запросе к сайту, а сайт верифицирует токен через API reCAPTCHA
API демоПримеры кода
Быстрый стартFunCaptcha
- 160,00 ₽
- Цена за 1000
- 0 сек.
- Скорость решения
Процесс решения FunCaptcha Arkose Labs заключается в следующем: мы забираем набор необходимых параметров со страницы ее размещения и передаем в сервис ruCaptcha, где ее решает работник, после чего нам возвращается ответ в виде набора уже других параметров, который необходимо передать в соответствующие поля для решения капчи
Примеры кода
Быстрый стартGeeTest CAPTCHA
- 160,00 ₽
- Цена за 1000
- 0 сек.
- Скорость решения

Процесс решения GeeTest Captcha заключается в следующем: мы забираем набор необходимых параметров со страницы ее размещения и передаем в сервис ruCaptcha, где ее решает работник, после чего нам возвращается ответ в виде набора уже других параметров, который необходимо передать в соответствующие поля для решения капчи
API демоПримеры кода
Быстрый стартreCAPTCHA Enterprise
- 65,00 ₽ — 160,00 ₽
- Цена за 1000
- 0 сек.
- Скорость решения
Процесс решения reCAPTCHA Enterprise заключается в следующем: определяем тип reCAPTCHA, он может быть V2 или V3, после чего мы забираем параметры капчи, необходимые для ее решения в виде параметра data-sitekey и адреса страницы размещения капчи и передаем их в сервис ruCaptcha, где ее решает работник, после чего нам возвращается ответ в виде токена, который необходимо ввести в соответствующее поле для решения капчи
Примеры кода
Быстрый стартБольше анти капча решений:
- Простая капча
- Текстовая капча
- Click капча
- Rotate капча
- reCAPTCHA V2 Callback
- KeyCAPTCHA
- reCAPTCHA V2 Invisible
- Capy Puzzle CAPTCHA
Простая капча
- 18,00 ₽ — 44,00 ₽
- Цена за 1000
- 0 сек.
- Скорость решения

Процесс решения обычной капчи заключается в следующем: мы забираем изображение капчи со страницы ее размещения и передаем в сервис ruCaptcha, где ее решает работник, после чего нам возвращается ответ, который необходимо ввести в соответствующее поле для решения капчи
API демоПримеры кода
Быстрый стартТекстовая капча
- 18,00 ₽ — 44,00 ₽
- Цена за 1000
- 0 сек.
- Скорость решения
Процесс решения текстовой капчи заключается в следующем: мы забираем текстовый вопрос капчи со страницы ее размещения и передаем в сервис ruCaptcha, где ее решает работник, после чего нам возвращается ответ, который необходимо ввести в соответствующее поле для решения капчи
API демоПримеры кода
Быстрый стартClick капча
- 70,00 ₽
- Цена за 1000
- 0 сек.
- Скорость решения
Процесс решения заключается в следующем: мы забираем изображение капчи со страницы ее размещения и инструкцию, по каким картинкам необходимо кликать и передаем в сервис ruCaptcha, где ее решает работник, после чего нам возвращается ответ в виде набора координат точек на изображении, по которым необходимо кликнуть для решения капчи
API демоПримеры кода
Быстрый стартRotate капча
- 35,00 ₽
- Цена за 1000
- 0 сек.
- Скорость решения

Процесс решения Rotate Captcha заключается в следующем: мы забираем изображение капчи со страницы ее размещения и передаем в сервис ruCaptcha, где ее решает работник, после чего нам возвращается ответ в виде значения угла поворота изображения, на который необходимо повернуть изображение для решения капчи
API демоПримеры кода
Быстрый стартreCAPTCHA V2 Callback
- 65,00 ₽ — 160,00 ₽
- Цена за 1000
- 0 сек.
- Скорость решения
Процесс решения reCAPTCHA V2 Callback не отличается от аналогичного процесса решения reCAPTCHA V2: мы забираем параметры капчи, необходимые для ее решения в виде параметра data-sitekey и адреса страницы размещения капчи и передаем их в сервис ruCaptcha, где ее решает работник, после чего нам возвращается ответ в виде токена, который необходимо ввести в соответствующее поле для решения капчи. Иногда вы не найдете кнопки, отправляющей форму. Вместо нее может использоваться callback-функция.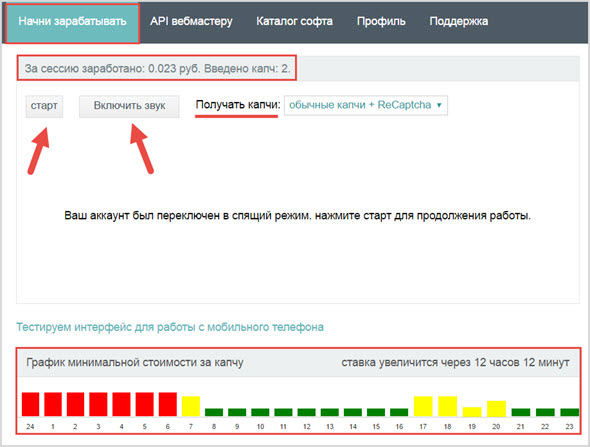 Эта функция выполняется, когда капча распознана. Обычно callback-функция определена в параметре data-callback или как параметр callback у функции grecaptcha.render
Эта функция выполняется, когда капча распознана. Обычно callback-функция определена в параметре data-callback или как параметр callback у функции grecaptcha.render
API демоПримеры кода
Быстрый стартKeyCAPTCHA
- 160,00 ₽
- Цена за 1000
- 0 сек.
- Скорость решения
Процесс решения KeyCaptcha заключается в следующем: мы забираем набор необходимых параметров со страницы ее размещения и передаем в сервис ruCaptcha, где ее решает работник, после чего нам возвращается ответ в виде набора уже других параметров, который необходимо передать в соответствующие поля для решения капчи
API демоПримеры кода
Быстрый стартreCAPTCHA V2 Invisible
- 65,00 ₽ — 160,00 ₽
- Цена за 1000
- 0 сек.
- Скорость решения
Процесс решения невидимой капчи reCAPTCHA V2 Invisible аналогичен распознаванию reCAPTCHA V2 и заключается в следующем: мы забираем параметры капчи, необходимые для ее решения в виде параметра data-sitekey и адреса страницы размещения капчи и передаем их в сервис ruCaptcha, где ее решает работник, после чего нам возвращается ответ в виде токена, который необходимо ввести в соответствующее поле для решения капчи
API демоПримеры кода
Быстрый стартCapy Puzzle CAPTCHA
- 160,00 ₽
- Цена за 1000
- 0 сек.
- Скорость решения
Процесс решения Capy Puzzle Captcha заключается в следующем: мы забираем набор необходимых параметров со страницы ее размещения и передаем в сервис ruCaptcha, где ее решает работник, после чего нам возвращается ответ в виде набора уже других параметров, который необходимо передать в соответствующие поля для решения капчи
Примеры кода
Быстрый стартРешение для обхода капч на GitHub
Полная документация и примеры кода по обходу капчи на GitHub
Как решить капчи на C++
C++ библиотека для распознавания капчи. Легкая интеграция API.
API для решения капчи на C++Как решить капчи на C#
C# библиотека для распознавания капчи. Легкая интеграция API.
API для решения капчи на C#Как решить капчи на Go
Golang модуль для обхода капчи онлайн. Быстрая интеграция API для решения капчи.
API для решения капчи на GoКак решить капчи на Java
Библиотека Java для быстрого обхода капчи.
API для решения капчи на Java Лучший сервис для решения капч. Простое API.Как решить капчи на PHP
Пакет PHP для автоматизации решения по обходу капчи. Лучший показатель успешного распознавания капчи.
API для решения капчи на PHPКак решить капчи на Python
Пакет Python скриптов для решения капчи на любом сайте. API интегрируется с любым скриптом. Лучше автоматическое решение по обходу капчи онлайн.
API для решения капчи на Python
 Лучший сервис для решения капч. Простое API.
Лучший сервис для решения капч. Простое API.Больше о сервисе распознавания капч
Полная документация и примеры кода по обходу капчи на PHP Python, Java, C#, Go.
Сервис основан на распознавании капчи работниками.
Используйте API обхода капчи для интеграции с любым программным обеспечением и отправки капч напрямую к работникам.
Сервис позволяет создать решение для обхода любой капчи.
Цена разгадывания капч
- Сервис использует ручной труд людей в распознавании изображений и, поэтому может распознать любую капчу, которую способен распознать человек. Особенно стоит отметить, что в сервисе распознаются не только текстовые капчи, но и графические капчи (reCAPTCHA V2, KeyCaptcha, FunCaptcha и другие). Стоимость распознавания очень низка, от 0,044 ₽ за одну капчу. Для удобства, все цены указываются за распознавание 1000 капч, но биллинг в системе происходит отдельно по каждой капче. Разные типы капч распознаются по разной цене.
- Простые капчи: 18,00 ₽ — 44,00 ₽ за 1000 решений. Простые капчи это те, где нужно переписать текст с изображения. Цена зависит от нагрузки на сервис. Если нагрузка маленькая, то цена низкая. Чем выше нагрузка на сервис, тем выше цена. В статистике можно узнать среднюю цену за каждый час за последние дни.
- reCAPTCHA v2: 65,00 ₽ — 160,00 ₽ за 1000 решений. Большая капча — это изображение, сумма высоты и ширины которого превышает 400 пикселей. Наш тариф фиксирован на 65,00 ₽ — 160,00 ₽ и не связан с нагрузкой на сервис. Изображения reCAPTCHA v2 — изображения из reCAPTCHA, где вам нужно выбрать соответствующие квадраты.
 Особенно стоит отметить, что в сервисе распознаются не только текстовые капчи, но и графические капчи (reCAPTCHA V2, KeyCaptcha, FunCaptcha и другие). Стоимость распознавания очень низка, от 0,044 ₽ за одну капчу. Для удобства, все цены указываются за распознавание 1000 капч, но биллинг в системе происходит отдельно по каждой капче. Разные типы капч распознаются по разной цене.
Особенно стоит отметить, что в сервисе распознаются не только текстовые капчи, но и графические капчи (reCAPTCHA V2, KeyCaptcha, FunCaptcha и другие). Стоимость распознавания очень низка, от 0,044 ₽ за одну капчу. Для удобства, все цены указываются за распознавание 1000 капч, но биллинг в системе происходит отдельно по каждой капче. Разные типы капч распознаются по разной цене.
Скидки на сервис
Если вы тратите больше 90 000,00 ₽ ежедневно в течение месяца и не являетесь рефералом кого-либо и также не используете зарегистрированный в нашем каталоге софт, можете написать в раздел «Support” и мы сделаем скидку.
Пополняйте баланс на любую сумму от 44,00 ₽ и работаете по самым низким из возможных тарифов. При этом неважно сколько капч отправляете: одну в месяц или 100 000 в день. Сервис работает по единым правилам со всеми заказчиками.
Расширение для обхода капчи
Расширение для браузера позволяет автоматически решать капчи найденные на любом сайте
Добавить в браузер
Текстовая CAPTCHA в 2022 / Хабр
В этой статье я попробую пройти весь путь в распознавании text-based CAPTCHA, от эвристик до полностью автоматических систем распознавания. Попробую проанализировать, жива ли еще капча(речь про текстовую), или пора ей на покой.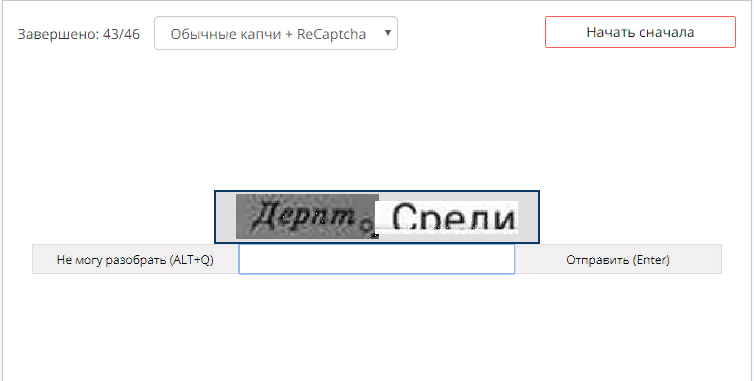
Впервые текстовая капча(text-based CAPTCHA), дальше я ее буду называть просто капча, использовалась в поисковике AltaVista, это был 1997 год, она предотвращала автоматическое добавление URL в поисковую систему. В те годы это была надежная защита от ботов, но прогресс не стоял на месте, и эту защиту начали обходить, используя доступные на то время OCR(например, FineReader).
Капча начала усложняться, в неё добавляли небольшой шум, искажения, чтобы распространенные OCR не могли распознать текст. Тогда начали появляться написанные под конкретные капчи OCR, что требовало дополнительных затрат и знаний у атакующей стороны. И от разработчиков капчей требовалось понимание, в чем сейчас трудности у атакующего, и какие искажения нужно внести, чтобы было сложно автоматизировать распознавание капчи. Часто из-за непонимания, как работает OCR, вносились искажения, которые больше создавали проблем человеку, чем машине. OCR для разных типов капч писались с использованием эвристик, и одним из сложных этапов была сегментация капчи на отдельные символы, которые потом можно было легко распознать с помощью тех же CNN(например LeNet-5), да и SVM покажут неплохой результат даже на сырых пикселях.
В качестве объекта распознавания возьму капчу Яндекса с сайта Yandex.com. На русскоязычной версии сайта капчи немного сложнее из-за того, что используются как русские, так и английские слова.
Примеры капчНа первый взгляд, достаточно правильно бинаризировать картинку(перевести в черно-белый вариант) и дело в шляпе, можно получить большой процентов правильных распознаваний, так как сегментация на отдельные буквы выглядит довольно простой.
Для снижения эффективности эвристических алгоритмов Яндекс сделал упор на сложность бинаризации: есть капчи, для которых в каждой области изображения будет свой порог бинаризации, и надо подбирать его адаптивно. В среднем капча содержит 14 символов. Даже если мы сделаем классификатор с точностью 99%, и все капчи будем правильно сегментировать, то это нам даст точность в 87% распознавания всей капчи из двух слов. Здесь еще стоит упомянуть, что на сложность модели влияет количество классов(букв, цифр, знаков), используемых во всем наборе капч — чем их больше, тем сложнее достичь высоких процентов распознавания отдельных символов на простых моделях, поэтому капча на яндекс. ру будет сложнее, т.к. в ней используются русские и английские слова.
ру будет сложнее, т.к. в ней используются русские и английские слова.
Из слабых мест этой капчи можно отметить, что буквы легко сегментируются при правильной бинаризации, и можно использовать проверку по словарю.
Далее будет описан эвристический алгоритм распознавания, а также я оставлю здесь ссылку на обучающую и тренировочную выборки.
Подготовительный этап
Для начала скачаем капчи и разделим их на тренировочную выборку и тестовую. Скачивание изображений капчи происходило через ВПН(с сайта yandex.com). При попытке сделать аккаунт вручную через браузер система меня распознавала ботом(думаю, из-за ВПН). Поэтому, предполагаю, я получил капчи с повышенной сложностью — «Если на втором этапе мы по-прежнему считаем запрос подозрительным, но степень уверенности в этом не такая высокая, то показываем простейшую капчу. А вот если мы уверены, что перед нами робот, то можем сложность и приподнять. Простое, но эффективное решение. » https://habr.com/ru/company/yandex/blog/549996/ Тип браузера, похоже, на результат не влиял (Opera, Chrome, Edge).
Итого набралось 4847 капч в тренировочную выбрку, и 354 — в тестовую. На распознавание обеих выборок было потрачено несколько долларов на сервисе decaptcher.com.
Эвристический алгоритм распознавания
Алгоритм будет состоять из нескольких шагов, это бинаризация, очистка от шума, извлечение двух слов, при необходимости — нормализация наклона для каждого слова, потом сегментация и распознавание.
1. Бинаризируем картинку — перевод цветного изображения, или изображения в градациях серого в черно-белое изображения. Цель — получение фона(0) и объекта(1), и уменьшение шума после бинаризации. Алгоритмы бинаризации будут описаны ближе к концу. Далее для каждого этапа сформируем параметры, которые будем потом оптимизировать. С этого момента работаем только с бинарным изображением.
2. Бинарное изображение очищаем от шума. Извлекаем связанные области из изображения — это наши объекты. Далее по количеству пикселей, которые входят в объект, разделяем их на шум и полезный объект.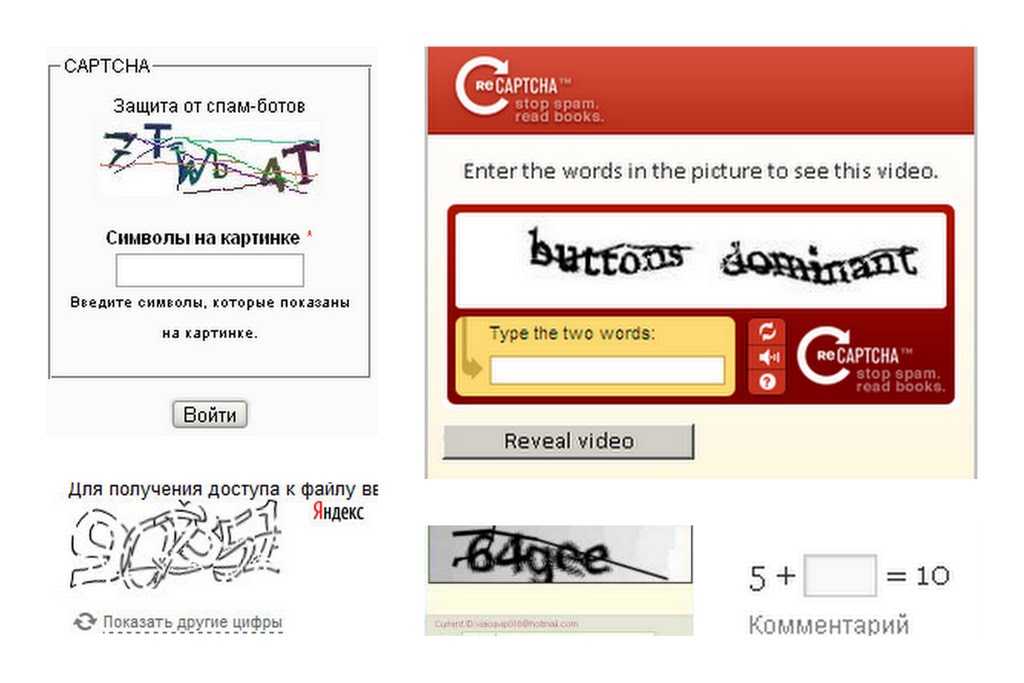 Все, что входит в наш интервал от А до В (по числу пикселей), это полезные объекты, остальное отсеиваем. В этом случае, например, у буквы i точка может быть определена как шум, чтобы этого не происходило, введем еще третью величину, расстояние С, это расстояние шума малого размера(эту величину мы тоже будем подбирать) до полезного объекта. Параметры А,В и С найдем простым перебором на тренировочном наборе, где максимизируем количество правильно распознанных капч.
Все, что входит в наш интервал от А до В (по числу пикселей), это полезные объекты, остальное отсеиваем. В этом случае, например, у буквы i точка может быть определена как шум, чтобы этого не происходило, введем еще третью величину, расстояние С, это расстояние шума малого размера(эту величину мы тоже будем подбирать) до полезного объекта. Параметры А,В и С найдем простым перебором на тренировочном наборе, где максимизируем количество правильно распознанных капч.
3. Извлекаем из изображения 2 слова. Пробел между словами находится примерно по центру изображения. Величину «примерно» будем искать в окне ширины X, это будет еще одним параметром для оптимизации. Далее получаем горизонтальную гистограмму яркости в этом окне, вводим еще одно значение — порог, который будет нам показывать в этом столбце пробел, или объект, наибольшее кол-во пробелов подряд будут нам говорить о том, что это место разделения двух слов. В этой процедуре нам нужно подобрать 2 параметра, оптимальная ширина окна в центре изображения, и порог, который нам показывает, объект это, или пробел.
В этой процедуре нам нужно подобрать 2 параметра, оптимальная ширина окна в центре изображения, и порог, который нам показывает, объект это, или пробел.
4. Нормализация наклона текста(для тех капч, где она нужна). Чтобы получить точность распознавания отдельных букв выше, нужно в некоторых капчах нормализовать наклон. Для этого мы проводим морфологическую операцию закрытие, и у нас получается единый объект. Далее находим ориентацию этого объекта, это угол между осью Х и главной осью элипса, в который вписывается наш объект.
Примеры нормализации наклона5. Сегментация. На этом этапе у нас есть изображения 2-х слов, теперь нужно разбить их на отдельные буквы, для дальнейшего распознавания. Так как в нашем случае буквы не соприкасаются вместе, то можем извлечь связные области из изображения, это и будут наши символы, пригодные для дальнейшего распознавания.
Примеры символов извлеченные из двух изображений6. Распознавание символов. Для распознавания я использовал сверточную сеть Lenet-5, только в моем случае классов было 26, в оригинале — 10. Для предобучения сети я сделал выборку в 52 тыс. изображений букв(по 2 тыс. на класс), отобрал несколько шрифтов, добавил различные искажения и обучил сверточную сеть. Подбирая параметры к алгоритму бинаризации и сегментации, мы получаем выборку для обучения классификатора. Эта выборка будет использована на втором и последующих шагах обучения классификатора, первый шаг обучения проходил с искуственно сгенерированными символами. Процесс итерационный, итого я смог насобирать 47 тыс. изображений букв с капч. Классы распределялись неравномерно, но это ожидаемо, так как в капче используют слова, а не случайные наборы букв. Итоговый классификатор имел точность 98.48%.
Для распознавания я использовал сверточную сеть Lenet-5, только в моем случае классов было 26, в оригинале — 10. Для предобучения сети я сделал выборку в 52 тыс. изображений букв(по 2 тыс. на класс), отобрал несколько шрифтов, добавил различные искажения и обучил сверточную сеть. Подбирая параметры к алгоритму бинаризации и сегментации, мы получаем выборку для обучения классификатора. Эта выборка будет использована на втором и последующих шагах обучения классификатора, первый шаг обучения проходил с искуственно сгенерированными символами. Процесс итерационный, итого я смог насобирать 47 тыс. изображений букв с капч. Классы распределялись неравномерно, но это ожидаемо, так как в капче используют слова, а не случайные наборы букв. Итоговый классификатор имел точность 98.48%.
Теперь, в зависимости от метода бинаризации, я представлю результаты распознаваний. Сначала я использовал один порог бинаризации для всех капч, порог подобрал на тренировочной выборке, и получил 15% правильно распознанных капч на тренировочной и 15% на тестовой.
Использование алгоритма Оцу дало 13.6% на тренировочной и 12.25% на тестовой.
Метод бинаризации Sauvola, после подбора параметров он дал 26.01% на тренировочной и 25.8% на тестовой.
Подметив, что капчи можно разделить по фону на группы, сделаем кластеризацию. Признаки извлечем с помощью метода Zoning. Суть метода такова — изображение делится на непересекающиеся области заданного размера, после чего извлекаем из каждой области среднее значение яркости. Чем меньше у нас размер окна, тем точнее описывается изображение. Для разделения на кластеры используем алгоритм кластеризации k-means. Классические методы определения оптимального количества кластеров показывали 2 кластера. Эмпирически я выбрал количество кластеров равное 5. Разбивка по кластерам получилась такая: в первом — 842 шт, во втором — 1300 шт, в третьем -1237 шт, в четвертом — 770 шт, в — пятом 698 шт изображений. Для каждого кластера подбираем свои параметры бинаризации алгоритма Sauvola на тренировочном наборе. В итоге получаем точность в 31.22%, на тестовом — 30.8%.
В итоге получаем точность в 31.22%, на тестовом — 30.8%.
Примеры кластеров:
Кластер 1Кластер 2Кластер 3Кластер 4Кластер 5Теперь у нас есть капчи, которые мы правильно бинаризировали, можно попробовать что-нибудь потяжелее, например U-Net для бинаризации, сеть с 13.5+ млн. параметров. Получили на тренировочных данных 39,2% правильных ответов, на тесте — 38.7%.
Для каждого нового типа капч, нам приходилось бы придумывать какие то новые схемы бинаризации, сегментации, что делает задачу трудоемкой в зависимости от капчи, но не невозможной. И затраты на разработку такой системы был порогом, который не каждый мог преодолеть для автоматического распознавания капчи и использования сервиса ботами.
А что на счет полностью автоматизированного процесса создания модели для распознавания, где не надо ничего придумывать, никакой эвристики? На вход — капчи с ответами, на выходе — готовая модель. Относительно недавно на сайте библиотеки Keras появились исходники, которые, при небольшой модификации, можно использовать для распознавания любых текстовых капч https://keras.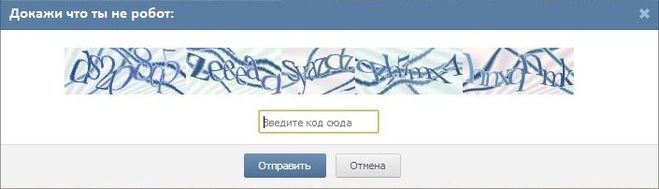 io/examples/vision/captcha_ocr/
io/examples/vision/captcha_ocr/
На Яндекс капче у меня получились такие цифры: на тренировочных данных сеть показала точность 55%, на тестовых — 39%. Из-за слишком маленькой тренировочной выборки для такой большой сети происходило быстро переобучение, но при правильно подобранных параметрах регуляризации сеть могла обучаться. Если увеличить тренировочную выборку, добавив туда отраженные картинки, то получим на тренировочных 58% точности, а на тесте — 43%. Увеличение тренировочной выборки новыми капчами даст еще прирост правильных ответов.
Сеть чаще всего ошибается на капчах такого вида:
Типы капч на которых система чаще всего ошибаетсяЭто коррелирует с тезисом авторов Яндекс капчи, в своей статье они писали -«Наиболее сложные датасеты с распознаванием слов на сегодняшний день представляют собой сильно искривлённые тексты (irregular text recognition).» Но в данном случае это скорее ограничение архитектуры используемой сети. Полученные фичи после слоев CNN мы распознаем lstm слоем последовательно слева направо, и в некоторых срезах возможного символа у нас находится сразу несколько символов. Это легко показать, сделав набор вот таких «капч»(рис. 1 ) в 10 тыс тренеровочных и 1 тыс тестовых. Обучив сетку, получим правильных ответов всего 20%, и 80% ошибок.
Это легко показать, сделав набор вот таких «капч»(рис. 1 ) в 10 тыс тренеровочных и 1 тыс тестовых. Обучив сетку, получим правильных ответов всего 20%, и 80% ошибок.
Но если сделать капчи, написав текст в одну строчку и добавив в текст искажения, усложняя ее (рис. 2), то получим 97% правильных ответов и 3% ошибочных.
Рис. 2Для увеличения процента успешных распознаваний яндекс капч можно использовать детектор текста, после чего нормализовать наклон и далее распознать нейронной сетью. Примеры сложных яндекс капч и детектора текста(рис. 3)
Рис. 3Если использовать детектор текста, то мы получим на тренировочных 60% точности, а на тесте — 51%. Я использовал уже предобученный на синтетике детектор текса — CRAFT: Character-Region Awareness For Text detection, а распознаванием отдельных слов занималась уже обученная модель на самой Яндекс капче.
Разработчики из Яндекса при проектировании капчи решали сразу две проблемы — уменьшение потенциальной эффективности ОЦР при «дружелюбности» для человека. Но чаще встречается такой подход к созданию текстовых капч — если человеку трудно ее распознать, то сложно и машине(рис. 4)
Но чаще встречается такой подход к созданию текстовых капч — если человеку трудно ее распознать, то сложно и машине(рис. 4)
Но это не так, нейронные сети без труда «ломают» такие капчи и могут показать уровень расознавания выше человеческого. При этом не нужно придумывать какие-то эвристические алгоритмы, достаточно скачать готовую сетку и обучить, 99% текстовых капч она решит.
Если подвести итог, то проектирование текстовой капчи в текущих реалиях требует понимания методов и подходов, которыми будет пользоваться злоумышленник для ее распознавания и исходя из этого проектировать капчу, которая эффективно сможет противостоять роботам, и при этом будет простой для восприятия человеком.
Прошу вас поделиться своими мыслями в комментариях, как может выглядеть текстовая капча, которая будет сложной для распознавания машиной.
Проблемы со входом в Яндекс
- Не могу войти под своим логином
- Некоторые приложения внезапно потеряли доступ к вашему аккаунту
- Яндекс просит ввести символы CAPTCHA
- Вы получили сообщение об ошибке «Ответ OCSP недействителен пока» в Firefox
Если вы не можете войти в свою учетную запись, воспользуйтесь нашими рекомендациями. Подробные инструкции для каждой ошибки приведены ниже.
Подробные инструкции для каждой ошибки приведены ниже.
- Неверное имя пользователя/пароль! Ошибка входа.
Если вы используете или использовали двухфакторную аутентификацию, для входа вам потребуется одноразовый пароль, сгенерированный приложением Яндекс.Ключ.
Попробуйте ввести логин и пароль прямо на странице Яндекс ID. Убедитесь, что Caps Lock отключен, а язык клавиатуры установлен на английский.
Примечание. Введите имя пользователя и пароль и не копируйте их из буфера обмена, потому что вы можете случайно скопировать лишний пробел и не сможете войти в систему.
На ПК и мобильных телефонах некоторые программы (например, Punto Switcher) может «автокорректировать» введенные вами символы: изменять написание, заменять заглавные буквы строчными, ставить пробел после точки и т. д. Прежде чем вводить пароль, убедитесь, что автоисправление опечаток и верстка отключены.
- Пользователь с указанным именем не найден.
Учетная запись с таким именем пользователя не существует или была удалена.
Перед обращением в службу поддержки еще раз проверьте правильность написания вашего имени пользователя:
Имена пользователей могут содержать только латинские буквы, цифры, точки и дефисы.
При вводе адреса электронной почты убедитесь, что вы вводите его правильно:
<ваше имя пользователя>@yandex.com.Вы можете войти только с помощью своего адреса Яндекс Почты. Адрес Gmail или Mail.ru не подойдет.
- Ваш аккаунт заблокирован.
Убедитесь, что вы правильно ввели свое имя пользователя. Если вы уверены, что имя пользователя указано правильно, обратитесь в службу поддержки, используя ссылку, указанную в сообщении об ошибке.
- Ошибка файлов cookie
Вы не сможете войти в Яндекс, если в вашем браузере отключены файлы cookie. Дополнительные сведения об этом параметре см. в разделе Настройки файлов cookie.
- Если больше ничего не работает
Попробуйте восстановить доступ для сброса пароля.
Всегда быстрее и проще сбросить пароль автоматически, чем обращаться в службу поддержки, поэтому сначала попробуйте все возможные автоматические варианты. Если не получается восстановить доступ через СМС или электронную почту, постарайтесь запомнить ответ на контрольный вопрос. При ответе на секретный вопрос убедитесь, что вы вводите ответ правильно и используете соответствующую раскладку клавиатуры.
Если Вам не удалось восстановить доступ самостоятельно, пожалуйста, заполните форму Восстановления доступа.

Если вы изменили свой пароль или нажали «Выход» на всех компьютерах, вам потребуется снова войти в браузер и большинство приложений, использующих вашу учетную запись.
Примечание. Приложения теряют доступ к вашей учетной записи, поскольку все токены OAuth отзываются, когда вы меняете пароль и выходите из системы со всех компьютеров.
Если Яндекс просит вас ввести символы CAPTCHA при входе в аккаунт, это означает, что в последнее время с вашего IP-адреса слишком много раз вводился неверный пароль.
Это может быть, если:
Вы несколько раз подряд неправильно ввели логин или пароль на Яндексе.
Другие пользователи вашей локальной сети (рабочей или домашней) несколько раз подряд ввели неверное имя пользователя или пароль. Обратитесь к сетевому администратору для решения этой проблемы.
Вы ввели неверное имя пользователя или пароль для почтовой программы (например, Outlook, Thunderbird, Mail и почтового клиента Opera).
Ваш компьютер был заражен вирусом, который пытался подобрать пароль от вашего аккаунта на Яндексе. Мы рекомендуем запустить онлайн-антивирусную программу, чтобы проверить компьютер на наличие вирусов. Многие производители антивирусного программного обеспечения предлагают бесплатные версии своих программ.
На вашем компьютере не установлено правильное системное время. Убедитесь, что часовой пояс в настройках операционной системы соответствует вашему местоположению и сверяйте время с Яндекс.Временем.
Убедитесь, что часовой пояс в настройках операционной системы соответствует вашему местоположению и сверяйте время с Яндекс.Временем.
Чтобы узнать, как установить время в разных операционных системах, см. раздел Установка часового пояса, даты и времени.
Связаться со службой поддержки
javascript — Ответ Anti-Captcha на форму
спросил
Изменено 3 года, 5 месяцев назад
Просмотрено 934 раза
Я пытаюсь передать форму с https://supremenewyork.com/checkout (Если веб-страница перенаправляет вас в магазин, добавьте какой-нибудь товар и повторите попытку)
В нем есть reCAPTCHA, поэтому я решил воспользоваться сервисом anti-captcha.com.
Я успешно разобрался с запросами на получение ответа капчи по ключу сайта и ссылке на веб-страницу (https://supremenewyork. com/checkout), но как я могу использовать это на странице?
com/checkout), но как я могу использовать это на странице?
Я пробовал этот код:
$('script[src="https://www.gstatic.com/recaptcha/api2/v1520836262157/recaptcha__ru.js"]').remove()
$('скрипт[src="https://www.google.com/recaptcha/api.js"]').remove()
$('.g-recaptcha').удалить()
for (пусть i = 0; i < $('body > div').length; i++) {
если ($('тело > div').eq(i).find('iframe').length > 0) {
if ($('body > div').eq(i).find('iframe').attr('src').indexOf('www.google.com/recaptcha') > -1) {
$('тело > div').eq(i).find('iframe').remove()
}
}
}
$('[имя=\'фиксация\']')
.before(``)
Но это не работает. Когда я нажимаю кнопку «обработать платеж», он перенаправляет меня на страницу типа «Ваша карта была отклонена», но если вы проверите исходящие запросы на вкладке «Сеть» в браузере, вы увидите, что в ответе checkout.json будет ‘ Причина сбоя: null’ — это означает, что запрос был сделан некорректно.