Повысить уникальность текста — проверка на антиплагиат
Задать вопрос
1
ЗАГРУЗИТЕ ФАЙЛ
Документ должен быть в формате .docx и размером не более 4Мб
2
ВЫБЕРИТЕ НАСТРОЙКИ
Укажите процент уникальности текста, который вам требуется
3
УКАЖИТЕ СИСТЕМУ
Выберите систему для которой хотите проверить или повысить уникальность
4
ОПЛАТИТЕ УСЛУГУ
Оплатите услугу с помощью самых популярных платежных систем
5
ПОЛУЧИТЕ ГОТОВЫЙ РЕЗУЛЬТАТ
Получите файл с высоким процентом оригинальности текста и свои заслуженные 5 баллов
71843 студентов прошли проверку на Антиплагиат
Повышение или проверка на уникальность для Antiplagiat.ru, Antiplagiat.ВУЗ
Повышение или проверка на уникальность для ETXT Антиплагиат и Руконтекст
Повышение или проверка на уникальность для Text.ru
Повышение или проверка на уникальность по всем системам Антиплагиат
Почему студенты выбирают наш сервис?
РАБОТАЕМ КРУГЛОСУТОЧНО
24 часа в сутки, 7 дней в неделю
МЫ — ЛИДЕРЫ
Наш сервис является лидером по количеству обработанных текст
АНОНИМНОСТЬ
Ваша работа никогда не попадет в публичный доступ. Мы это гарантируем
Мы это гарантируем
Как мы работаем
1:32
Отзывы довольных студентов
Мы публикуем только настоящие отзывы
студ. ЮУрГУ, Настя Ф.
Спасибо!!! Отличный сервис. Даже если не получилось повысить уникальность с первого раза, до нужного результата, служба тех поддержки все исправит… Читать далее «студ. ЮУрГУ, Настя Ф.»
студ. ЮГУ, Валерия Н.
Спасибо, помогли. Было сложно часами сидеть и пыхтеть над текстом, а уникальность совсем не поднималась, плюнула и пошла искать решение… Читать далее «студ. ЮГУ, Валерия Н.»
студ. ЮУрГУ, Михаил К.
От души хочу поблагодарить специалистов за помощь, помогли когда другие не смогли. Спасибо вам подняли уникальность с 20% до 85%… Читать далее «студ. ЮУрГУ, Михаил К.»
студ. Мифи, Мария А.
Добрый вечер! Безмерно благодарна всем, кто работает на этом сайте! Большое спасибо! Всё как в условиях, не первый раз… Читать далее «студ. Мифи, Мария А.»
студ. АлтГТУ, Максим В.
Были экзамены на носу, выручи очень подняли на 50% от моих. Долго бился сам с уникальностью, а толку мало было… Читать далее «студ. АлтГТУ, Максим В.»
Большое спасибо! Приятно было узнать,
Большое спасибо! Приятно было узнать, что уникальность моего текста — 100%!
Елена
Все быстро, для меня главное
Все быстро, для меня главное бесплатно, не было никакой лишней рекламы
Татьяна
Молодцы! Отличный сервис! Быстро и
Молодцы! Отличный сервис! Быстро и качественно!
Людмила
Всё хорошо. Уникальность текста ,
Всё хорошо. Уникальность текста , норм.
Лидия
Все отзывы Вконтакте
Популярные способы оплаты
Как начать работу с сервисом?
1
ЗАГРУЗИТЕ ФАЙЛ
Документ должен быть в формате .docx и размером не более 4Мб
2
ВЫБЕРИТЕ НАСТРОЙКИ
Укажите процент уникальности текста, который вам требуется
3
УКАЖИТЕ СИСТЕМУ
Выберите систему для которой хотите проверить или повысить уникальность
4
ОПЛАТИТЕ УСЛУГУ
Оплатите услугу с помощью самых популярных платежных систем
5
ПОЛУЧИТЕ ГОТОВЫЙ РЕЗУЛЬТАТ
Получите файл с высоким процентом оригинальности текста и свои заслуженные 5 баллов
1
ЗАГРУЗИТЕ ФАЙЛ
Документ должен быть в формате . docx и размером не более 4Мб
docx и размером не более 4Мб
2
ВЫБЕРИТЕ НАСТРОЙКИ
Укажите процент уникальности текста, который вам требуется
3
УКАЖИТЕ СИСТЕМУ
Выберите систему для которой хотите проверить или повысить уникальность
4
ОПЛАТИТЕ УСЛУГУ
Оплатите услугу с помощью самых популярных платежных систем
5
ПОЛУЧИТЕ ГОТОВЫЙ РЕЗУЛЬТАТ
Получите файл с высоким процентом оригинальности текста и свои заслуженные 5 баллов
ПОВЫСИТЬ УНИКАЛЬНОСТЬ ПРОВЕРИТЬ УНИКАЛЬНОСТЬ
Статьи
Все статьи
Антиплагиат АГТУ: что это такое и как им пользоваться?
Плагиат является серьезной проблемой в образовательной среде. Студенты и школьники знают, что при написании научных работ необходимо учитывать авторские права и следить за уникальностью текста. В университетах и школах принято проверять работы на плагиат, и если степень уникальности текста низка, работа может быть отклонена и отправлена на доработку.
(далее…)
13 Апр 2023
Что такое плагиат и уникальность
Цель данной статьи – дать представление вам о плагиате: что такое плагиат? – как понятие и явление, в каких представлен видах. О том, как с ним бороться на своих страницах – до полного выведения. В видео раскрываются основные приёмы, в каком-то смысле секреты для вас, которые помогут вам всегда держать на уровне уникальность ваших курсовых работ, а потом и дипломной.
(далее…)
29 Янв 2023
Что такое антиплагиат — какие программы существуют
Прочитав эту статью, вы узнаете что такое антиплагиат и как он работает. Если перед вами лежит готовая статья, реферат, курсовая или дипломная работа раскроем несколько секретов успешного прохождения проверки на уникальность, чтобы к работе не возникло вопросов со стороны проверяющего.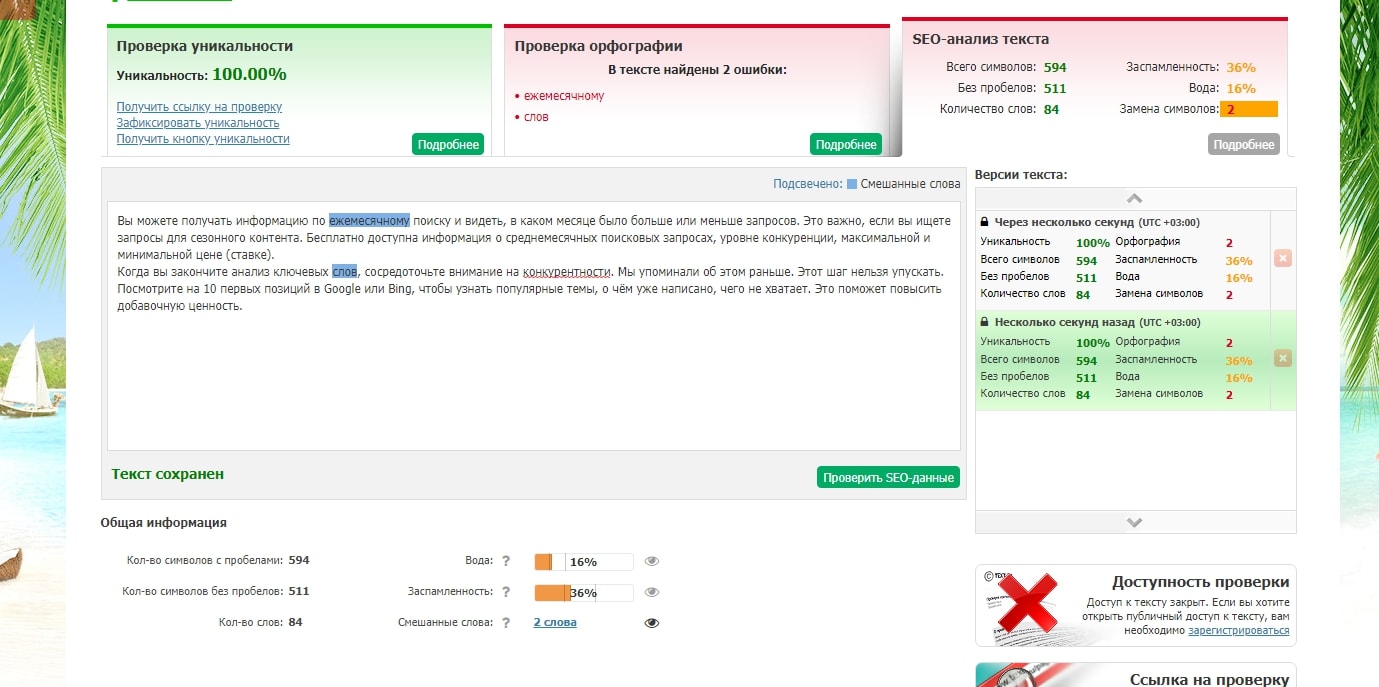
(далее…)
29 Янв 2023
Готовы получить уникальный текст
всего за 5 минут?
Сегодня 11 студентов повысили уникальность своих работ. А всего — 502931 студент
Задать вопрос
© 2023 Уникальность.рф. Все права защищены
support@уникальность.рф
ТОП-10 сервисов проверки уникальности текстов в 2023 [Подборка]
В этой статье вы узнаете:
- ТОП-10 сервисов для проверки уникальности текста в 2023 году.
- Как проверить текст на уникальность: пошаговая инструкция.
Содержание (развернуть ↴)
ТОП-10 сервисов для проверки уникальности текста
Начнем с основной части статьи — рассмотрим 10 лучших сервисов (и программ) для проверки уникальности текста. Это универсальные инструменты — они подойдут для блогеров, студентов, копирайтеров, вебмастеров, SEO-специалистов.
Text.ru
Text.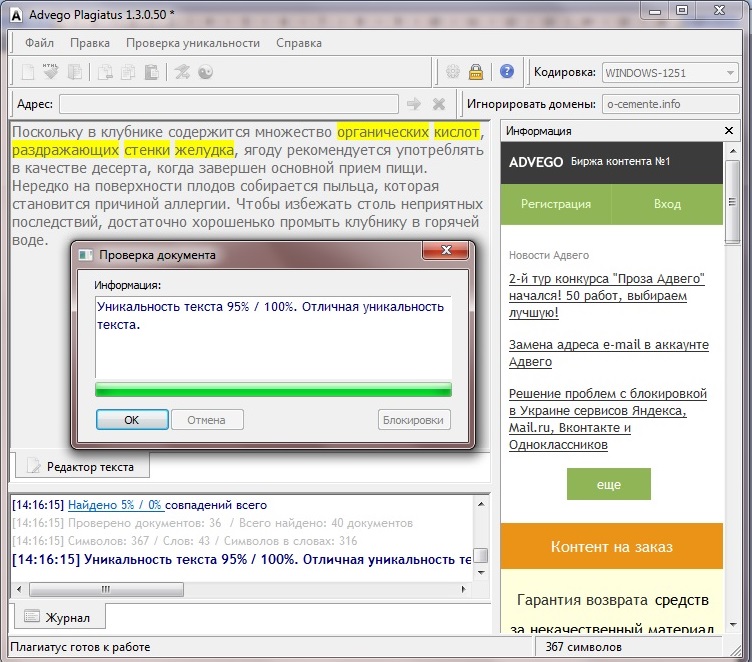 ru (Текст.ру) — бесплатный сервис проверки текста на уникальность. Инструмент работает в режиме онлайн.
ru (Текст.ру) — бесплатный сервис проверки текста на уникальность. Инструмент работает в режиме онлайн.
Глубокая и качественная проверка текстов на плагиат найдет дубликаты и рерайт. Эффективные алгоритмы платформы проводят глубокую и точную проверку текстов.
Также «Текст.ру» проверяет другие показатели текста:
- Количество символов: с пробелами и без пробелов.
- Количество слов.
- Орфографические ошибки.
- SEO-анализ: заспамленность, вода.
На сайте можно запустить проверку текстов по Яндекс.Дзен: например, чтобы написать уникальный материал для своего блога в «Дзене». Сохраняется история проверок — они отображаются во вкладке «Версии текста».
Начать работу можно без регистрации. Но для неавторизованных пользователей есть ограничения: можно проверить не более 15 000 символов в день. После регистрации лимит увеличится до 50 000 символов.
Проверить уникальность текста →
eTXT Антиплагиат
Антиплагиат — это онлайн-сервис, который доступен на бирже контента eTXT. Запустить проверку текста можно без регистрации — в этом доступен анализ текст объемом до 3 000 символов. После регистрации — до 5 000 знаков.
Запустить проверку текста можно без регистрации — в этом доступен анализ текст объемом до 3 000 символов. После регистрации — до 5 000 знаков.
На выбор есть два варианта проверки:
- Обнаружение рерайтинга. Используется для выявления фрагментов рерайтинга, сделанного путем перестановки слов или изменения формы.
- Обнаружение копий. Инструмент для поиска дословных совпадений.
Можно скачать программу «Антиплагиат eTXT» для компьютера. Она распространяется бесплатно.
Что умеет программа:
- Находить и выделять неуникальные фрагменты текста.
- Создавать подробные отчеты о проверке уникальности контента с возможностью настройки различных параметров поиска.
- Проверять на уникальность все страницы сайта, получая подробный отчет по сайту.
Проверить уникальность текста →
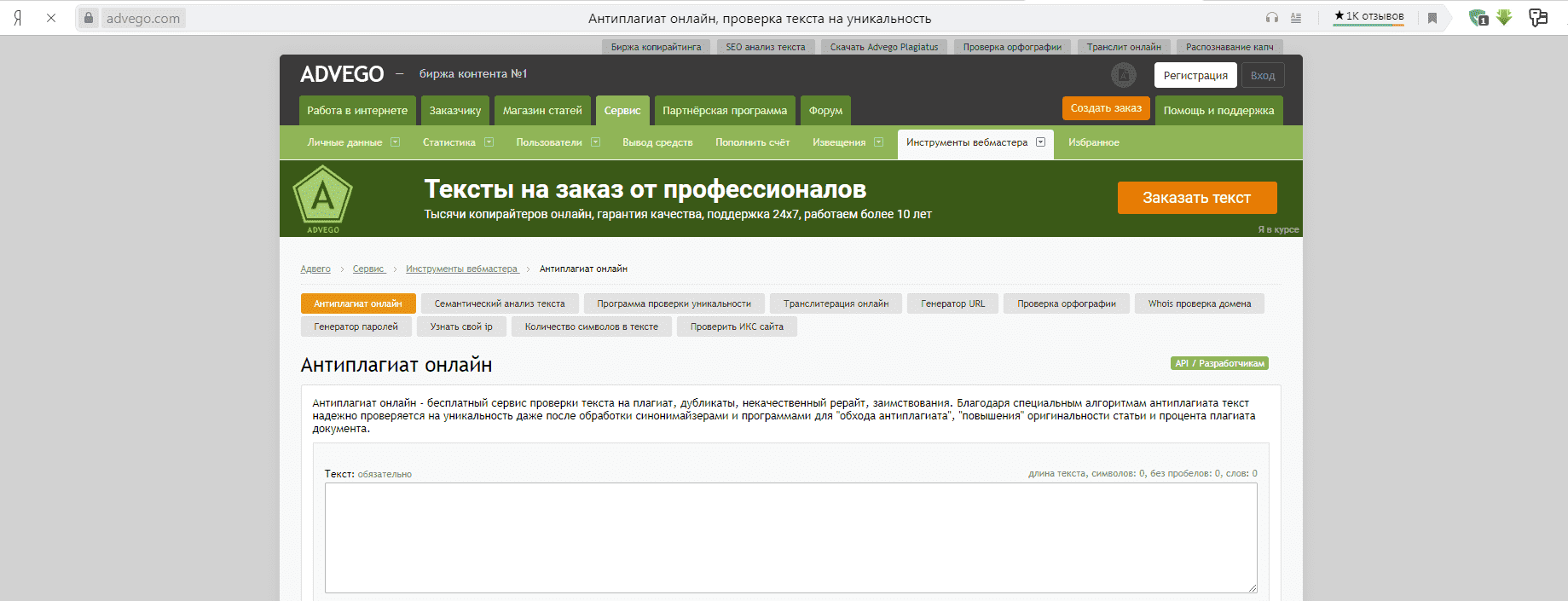
Advego Plagiatus и «Антиплагиат онлайн»
Advego Plagiatus — бесплатная программа для Windows от биржи контента «Адвего». Софт быстро находит неуникальные фрагменты в тексте — он определяет процент схожести вашего текстового документа с другими материалами в интернете. Это отличное решение для больших текстов.
Софт быстро находит неуникальные фрагменты в тексте — он определяет процент схожести вашего текстового документа с другими материалами в интернете. Это отличное решение для больших текстов.
Помимо программы, на сайте Advego есть инструмент «Антиплагиат онлайн». Это бесплатный сервис проверки текста на плагиат, дубликаты, некачественный рерайт и заимствования.
Чтобы начать проверку через «Антиплагиат онлайн», не нужно скачивать дополнительный софт на ПК. Проверка проводится в браузере.
Можно запустить анализ текста на разных языка:
- Русский.
- Китайский.
- Английский.
- Испанский.
- Немецкий.
Есть специальная защита от сервисов «обхода антиплагиата». Поэтому при проверке текста можно получить более точный вариант: например, при анализе курсовых или дипломных работ.
Проверить уникальность текста →
Content Watch
Content Watch — это полезный инструмент для проверки текстов. На сайте есть сервис, который определяет уникальность текстов — бесплатно, быстро и без регистрации.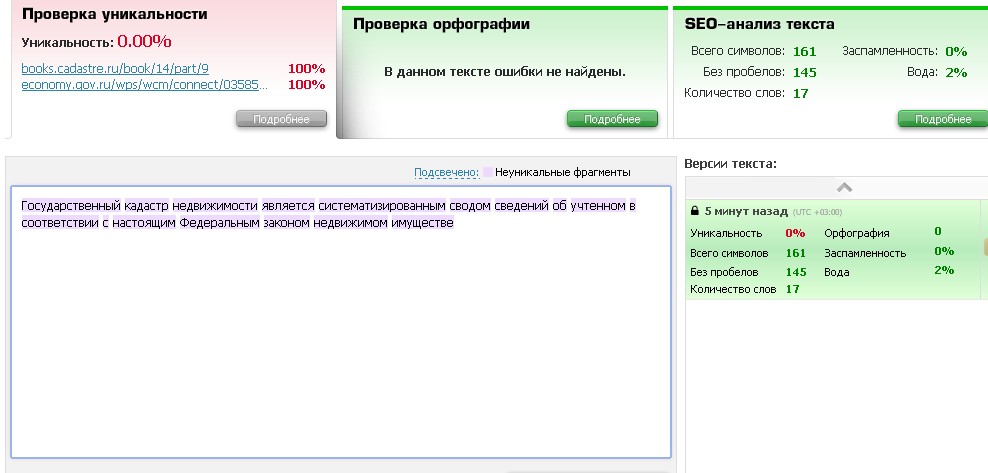
CW проводит тщательный анализ текста и поиск копий в интернете. Определяет рерайт и другие способы уникализации текста.
Можно запустить проверку сайта по URL-адресу.
В бесплатной версии есть ограничения:
- Текст длиной до 10 000 символов.
- До 3 проверок в день.
- Нельзя использовать средства автоматического доступа к сервису.
Проверить уникальность текста →
PR-CY
Антиплагиат от PR-CY — сервис бесплатной проверки уникальности текста. Инструмент ищет совпадения вашего текста с тем, что опубликовано на других веб-сайтах в интернете.
Особенности сервиса:
- Можно проверять на уникальность тексты до 5 000 символов.
- Количество проверок ограничено тарифным планом.
- Есть инструмент для игнорирования доменов. Можно указать сразу несколько доменов — сайтов, которые не будут учитываться при проверке уникальности материала.
Проверить уникальность текста →
Антиплагиат
Антиплагиат (Antiplagiat. ru) — это система обнаружения текстовых заимствований. Отлично подходит для проверки образовательных документов: курсовые и дипломные работы, рефераты, научные работы.
ru) — это система обнаружения текстовых заимствований. Отлично подходит для проверки образовательных документов: курсовые и дипломные работы, рефераты, научные работы.
Особенности инструмента:
- Более 1 миллиарда источников. Самая полная коллекция источников в России и странах СНГ.
- Время обработки документов — от 10 секунд.
- Более 85% студентов в ВУЗах России и стран СНГ подключены к системе «Антиплагиат».
Начать работу с онлайн-сервисом можно бесплатно.
Проверить уникальность текста →
Copywritely
Copywritely — удобный инструмент для студентов, копирайтеров, владельцев сайтов, SEO-специалистов, блогеров. На сайте можно быстро провести анализ контента сайта на уникальность.
Доступно два формата работы:
- Проверка текста. Нужно просто скопировать и вставить текст в специальный блок.
- Проверка URL. Нужно указать адрес страницы, которую вы хотите проверить на уникальность.
Также инструмент предоставляет рекомендации по вопросам грамматики, читабельности и ключевым словам.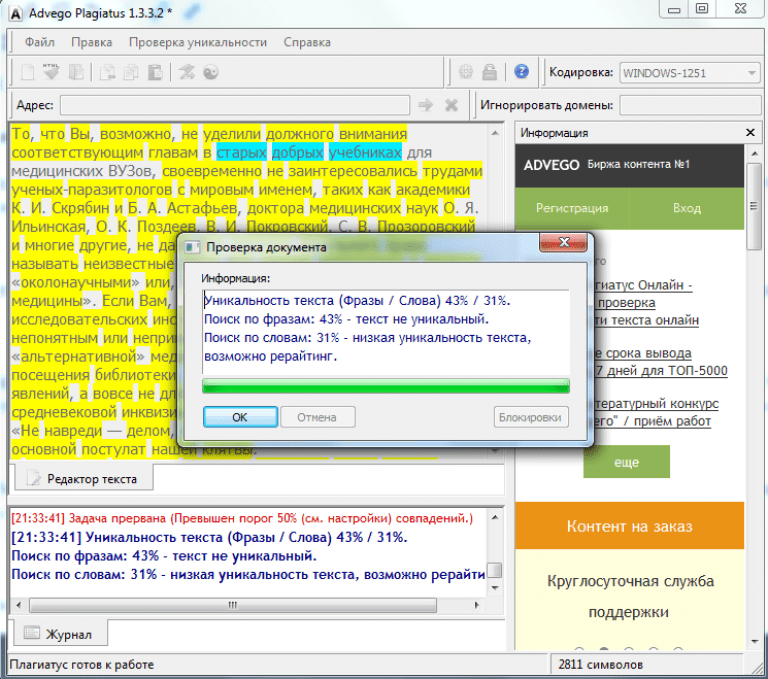
Проверить уникальность текста →
BE1
Антиплагиат на сайте BE1.ru — это удобный онлайн-инструмент для проверки уникальности текста. Для копирайтеров, SEO-специалистов, вебмастеров.
Ограничения сервиса:
- Длина текста для проверки — до 10 000 символов.
- Количество страниц сайта для проверки на уникальность — до 100 шт.
Есть несколько форматов проверки: можно вставить текст в строку ввода, получить материал по URL или загрузить документ из файла. Доступна функция исключения страниц из анализа.
Проверить уникальность текста →
Текстовод
Текстовод — бесплатный антиплагиат. Работать с сервисом можно без регистрации.
Для гостей — пользователей, которые не прошли регистрацию — есть ограничения: проверка текстов до 10 000 знаков. После регистрации лимит увеличится до 100 000 знаков.
На сайте есть вспомогательные сервисы:
- Инструмент для проверки орфографии.
- Синонимайзер.
- Авторерайт.
Проверить уникальность текста →
RusTXT
RusTXT — простой и удобный сервис для быстрой проверки уникальности текстов. Чтобы выявить плагиат, нужно: вставить текст в текстовое поле или загрузить документ в формате Word, PPT, TXT.
Чтобы выявить плагиат, нужно: вставить текст в текстовое поле или загрузить документ в формате Word, PPT, TXT.
Время выполнения анализа зависит — 10-20 секунд. Проверка может затянуться из-за большой очереди.
Также на сайте можно проверить орфографию и пунктуацию. Можно игнорировать домены.
Проверить уникальность текста →
Как проверить текст на уникальность: пошаговая инструкция
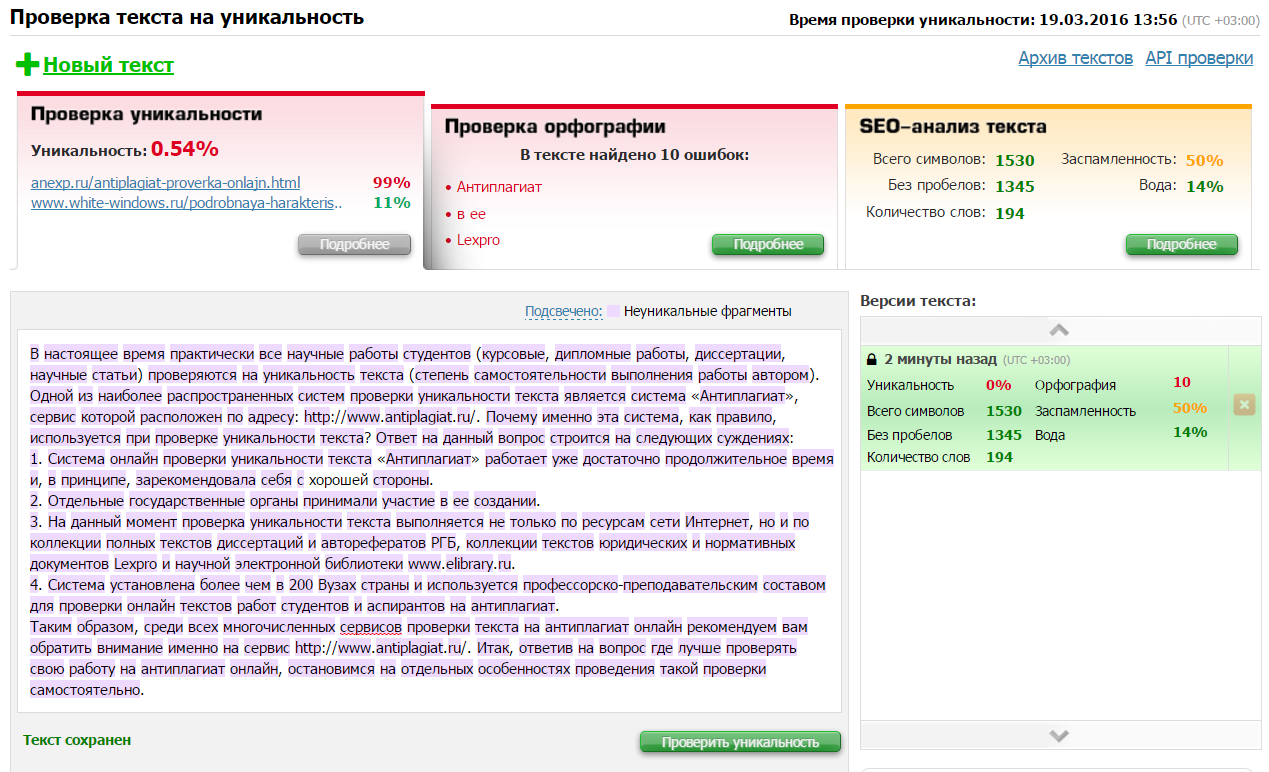
Перейдем к практической части статьи — проверим текст на уникальность. Для примера возьмем сервис Text.ru.
Зайдите на сайт онлайн-сервиса «Текст.ру». Вставьте нужный текст в специальное окно.
После того, как вы введете текст, система покажет общее количество символов материала. Чтобы начать работу, нажмите кнопку «Проверить на уникальность».
Запускаем проверку уникальности текстаАлгоритм платформы начнет анализ. Тексты проверяются в порядке очереди — свой номер в очереди можно посмотреть в левой верхней вкладки окна анализа.
Так отображается очередь на проверку текстовКогда закончится проверка, вы увидите:
- Уникальность текста.
 Система выделит неуникальные предложения и покажет источники, где есть аналогичные текстовые блоки.
Система выделит неуникальные предложения и покажет источники, где есть аналогичные текстовые блоки. - Орфографические ошибки.
- Заспамленность и процент «водности».
 Система выделит неуникальные предложения и покажет источники, где есть аналогичные текстовые блоки.
Система выделит неуникальные предложения и покажет источники, где есть аналогичные текстовые блоки.Проверить уникальность текста →
Итоги
Краткие итоги статьи:
- Проверить уникальность текста — легко. В этом помогут специальные онлайн-сервисы, которые анализируют текстовые документы и сайты.
- В статье представлены 10 лучших инструментов — сервисов и программ — для проверки уникальности. Используйте сразу несколько онлайн-сервисов, чтобы получить более точный результат проверки.
Глава 3 Доступность и уникальность
В этой главе показано, как проверить, доступны ли записи и/или полным в отношении набора ключей, и являются ли они уникальными. Описанные здесь проверки обычно полезны для данных в «длинном» формате, где один столбец содержит значение, а все остальные столбцы определяют это значение.
- Для проверки отсутствующих значений в отдельных переменных см. также 2.2.
- Чтобы проверить, заполнены ли записи или их части, см. 4.1.
 также 2.2.
также 2.2.Данные
В этой главе используется набор данных samplonomy , который поставляется с проверкой упаковка.
библиотека (подтвердить) данные (самплономия) head(samplonomy, 3)
## регион частота период значение измерения ## 1 Agria A 2014 г.в.п. 600000 ## 2 Agria A 2014 импорт 210000 ## 3 Agria A 2014 export 222000
3.1 Длинные данные
Набор данных выборки структурирован в «полной форме». Это означает, что каждый
запись имеет сингл значение столбец и один или несколько столбцов, содержащих
значения символов, которые вместе описывают, что означает значение.
головка(самплономия,3)
## регион частота период значение измерения ## 1 Agria A 2014 г.в.п. 600000 ## 2 Agria A 2014 импорт 210000 ## 3 Agria A 2014 export 222000
Набор данных содержит несколько временных рядов для нескольких показателей
вымышленной страны Самплония. Есть временные ряды для нескольких
субрегионы Самплонии.
Есть временные ряды для нескольких
субрегионы Самплонии.
Данные длинного формата обычно используются в качестве транспортного формата: они могут массовая загрузка данных в системы баз данных на основе SQL или для передачи данных между организации однозначно.
Данные в длинной форме, как правило, гораздо сложнее проверить и обработать для статистической цели, чем данные в широком формате, где каждая переменная хранится в отдельный столбец. Причина в том, что в длинноформатных отношениях между различные переменные разбросаны по записям, и эти записи не обязательно упорядочены каким-либо особым образом перед обработкой. Это делает интерпретация валидации по своей сути терпит неудачу для длинных данных, чем для широкоформатных данных.
Набор данных samplonomy имеет особенно неприятную структуру. Он содержит оба
годовые и квартальные временные ряды ВВП, импорта, экспорта и баланса
Торговля (экспорт минус импорт). Таким образом, столбец периода содержит как ежеквартальные
и годовые этикетки.
Естественно, мы ожидаем, что комбинации клавиш уникальны, что все временные ряды непрерывны и полны, что торговый баланс равен экспорту за вычетом импорта. везде значения этих районов складываются с провинциями, и эта провинция значения складываются в общую сумму Samplonia. Наконец, квартальные временные ряды должны в сумме соответствовать годовым значениям.
3.2 Уникальность
Функция is_unique() проверяет, являются ли комбинации переменных (обычно
ключевые переменные) однозначно идентифицируют запись. Он принимает любое положительное число
имена переменных и возвращает ЛОЖЬ для каждой записи, которая дублируется с
относительно обозначенных переменных.
samplonomy .
правило <- validator(is_unique(регион, период, мера)) out <- конфронтация (самплономия, правило) # показываем 7 столбцов вывода для удобочитаемости summary(out)[1:7]
## name items pass failed nNA error warning ## 1 V1 1199 1197 2 0 ЛОЖЬ ЛОЖЬ
2 сбоя. После извлечения личности
значения для каждой записи, мы можем найти дубликаты, используя
функция удобства от подтвердите .
нарушение(самплономия, выход)
## регион частота период значение измерения ## 870 Induston Q 2 кв. 2018 экспорт 165900 ## 871 Induston Q 2018Q2 export 170000
При интерпретации уникальности следует помнить о двух тонкостях. первое связано с пропущенными значениями, а второе связано с группировкой. Чтобы начать с проблемы пропущенного значения, взгляните на следующие две записи. кадр данных.
df <- data.frame(x = c(1,1), y = c("A",NA))
df ## х у ## 1 1 А ## 2 1
Как определить, уникальны ли эти две записи? Заманчивый вариант такой
сказать, что первая запись уникальна, и вернуть NA для второй записи
поскольку он содержит пропущенное значение: R имеет привычку возвращать NA из
расчеты, когда входное значение равно NA . Этот выбор не является недействительным, но он
будет иметь последствия для определения того, является ли первая запись уникальной, поскольку
хорошо. В конце концов, можно заполнить значение в отсутствующем поле, например
что две записи дублируются. Следовательно, если бы кто-то вернул
Этот выбор не является недействительным, но он
будет иметь последствия для определения того, является ли первая запись уникальной, поскольку
хорошо. В конце концов, можно заполнить значение в отсутствующем поле, например
что две записи дублируются. Следовательно, если бы кто-то вернул NA для
вторая запись, правильно будет также вернуть NA для первой
записывать. В R выбор сделан для обработки — дубликат из базы R). Чтобы увидеть это
проверьте следующий код и вывод.
df <- data.frame(x=rep(1,3), y = c("A", NA, NA))
is_unique(df$x, df$y) ## [1] TRUE FALSE FALSE
Вторая тонкость связана с группировкой. Вы можете проверить, является ли
столбец уникален, учитывая одну или несколько других переменных. Соблазнительно думать
что для этого требуется подход «разделить-применить-объединить», при котором набор данных сначала
разделить по одной или нескольким группирующим переменным, проверить уникальность
столбец в каждой группе, а затем объедините результаты. Однако такой подход
в этом нет необходимости, так как вы можете просто добавить группирующие переменные в список
переменные, которые вместе с должны быть уникальными.
Однако такой подход
в этом нет необходимости, так как вы можете просто добавить группирующие переменные в список
переменные, которые вместе с должны быть уникальными.
В качестве примера рассмотрим вывод следующих двух подходов.
# y уникален при данном x. Но не сам по себе df <- data.frame(x=rep(буквы[1:2],каждый=3), y=rep(1:3,2)) # подход "разделить-применить-объединить" unsplit(tapply(df$y, df$x, is_unique), df$x)
## [1] TRUE TRUE TRUE TRUE TRUE TRUE
# комбинированный подход is_unique(df$x, df$y)
## [1] ИСТИНА ИСТИНА ИСТИНА ИСТИНА ИСТИНА ИСТИНА ИСТИНА
3.3 Доступность записей
Этот раздел находится на проверке на наличие полных записей. Тестирование для отдельных пропущенные значения (NA) рассматривается в 2.2.
Мы хотим убедиться, что для каждого региона и каждой переменной периоды 2014,
2015, \(\ldots\), 2019 присутствуют. Используя contains_at_least , мы можем установить
этот.
правило <- валидатор(
содержит_по крайней мере(
ключи = data.frame(период = as.character(2014:2019))
, by=список(регион, мера))
)
out <- конфронтация (самплономия, правило)
# показываем 7 столбцов вывода для удобочитаемости
итог(выход)[1:7] ## элементы имени не проходят проверку, предупреждение об ошибке nNA ## 1 V1 1199 1170 29 0 FALSE FALSE
Функция contains_at_least разбивает набор данных samplonomy на блоки
по значениям регион и мерка . Далее проверяется, что в каждом
блок переменной период содержит как минимум значения 2014–2019.
Возвращаемое значение представляет собой логический вектор, в котором количество элементов равно
количество просматриваемых строк в наборе данных. это ИСТИНА для каждого блока
где присутствуют все годы, и ЛОЖЬ для каждого блока, где один или несколько из
лет отсутствует. В этом случае 29 записей помечены как FALSE. Эти
можно найти следующим образом.
Эти
можно найти следующим образом.
головка(нарушение(самплономия, выход))
## регион частота период значение измерения ## 1 Agria A 2014 г.в.п. 600000 ## 5 Agria Q1 2014Q1 ВВП 60000 ## 9 Agria Q2014 Q2 ВВП 120000 ## 13 Agria Q 2014Q3 ВВП 300000 ## 17 Agria Q4 2014Q4 ВВП 120000 ## 204 Agria Q1 2015Q1 ВВП 58200
Проверка этих записей показывает, что в этом блоке для Agria ВВП
для "2015" отсутствует.
Мы можем выполнить более строгую проверку и проверить, все ли для каждой меры кварталы "2014Q1" \(\ldots\) "2019Q4" присутствуют для каждой провинции ( Agria и Индастон ). Сначала создайте набор ключей для тестирования.
лет <- as.character(2014:2019)
четверти <- paste0("Q",1:4)
набор ключей <- expand.grid(
регион = c("Агрия", "Индастон")
, период = sapply (годы, paste0, кварталы))
головка(набор ключей) ## регион период ## 1 Агрия 2014Q1 ## 2 Индастон 2014Q1 ## 3 Агрия 2 кв.
 2014 г.
## 4 Индастон, 2 кв. 2014 г.
## 5 Агрия 3 кв. 2014 г.
## 6 Induston 2014Q3
2014 г.
## 4 Индастон, 2 кв. 2014 г.
## 5 Агрия 3 кв. 2014 г.
## 6 Induston 2014Q3 Этот набор ключей будет указан в правиле и передан против в качестве ссылки
данные.
правило <- валидатор(
содержит_по крайней мере (ключи = минимальные_ключи, по = мера)
)
out <- конфронтация(самплономия, правило
, ссылка = список (минимальные_ключи = набор ключей))
# показываем 7 столбцов вывода для удобочитаемости
итог(выход)[1:7] ## элементы имени не проходят проверку, предупреждение об ошибке nNA ## 1 V1 1199 899 300 0 FALSE FALSE
300 ошибок. Проверяя набор данных, как указано выше, мы
см., что для Induston export отсутствует в "2018Q3" .
Наконец, мы проводим строгий тест, чтобы проверить, что для каждого измерения все периоды и
сообщаются все регионы. Мы также требуем, чтобы не было больше и не меньше
записей, чем для каждой отдельной меры. Для этого функция contains_exactly можно использовать.
Сначала создайте набор ключей.
лет <- as.character(2014:2019)
четверти <- paste0("Q",1:4)
набор ключей <- expand.grid(
регион = с(
"Агрия"
, "Краудон"
, "Гринхэм"
, "Индастон"
, "Грязевая вода"
, "Ньюбэй"
, "Окдейл"
, "Самплония"
, "Дымный"
, "Уитон"
)
, период = с (годы, период (годы, паста0, кварталы))
)
головка (набор ключей) ## регион период ## 1 Агрия 2014 ## 2 Краудон 2014 ## 3 Гринхэм 2014 ## 4 Индастон 2014 ## 5 Грязевая вода 2014 ## 6 Ньюбэй 2014
Набор ключей передается правилу в качестве справочных данных с использованием и .
правило <- валидатор (содержит_точно (все_ключи, по = мере))
out <- конфронтация(самплономия, правило
, ссылка = список (all_keys = набор ключей))
# показываем 7 столбцов вывода для удобочитаемости
summary(out)[1:7] ## name items pass failed nNA error warning ## 1 V1 1199 600 599 0 FALSE FALSE
Чтобы найти, где находятся ошибки, мы сначала выбираем записи с ошибкой и
затем найдите уникальные меры, встречающиеся в этих записях.
ошибочные_записи <- нарушение(самплономия, вне) unique(erroneous_records$measure)
## [1] "gdp" "export"
Итак, здесь в блоках, содержащих GDP и Export, отсутствуют целые записи.
3.4 Пробелы в (временных) рядах
Для временных рядов или, возможно, других рядов желательно, чтобы существует постоянное расстояние между каждыми двумя элементами ряда. Математический термин для такого ряда называется линейной последовательностью . Вот несколько примеров линейных рядов.
- Натуральные числа: \(1,2,3,\ldots\)
- Четные натуральные числа \(2, 4, 6, \ldots\)
- Кварталы:
"2020Q1","2020Q2", \(\ldots\) - лет (это просто натуральные числа): \(2019, 2020, \ldots\)
проверка функций is_linear_sequence и in_linear_sequence проверка
представляет ли переменная линейный ряд, возможно, в блоках, определяемых
категориальные переменные. Они могут использоваться интерактивно или, как правило, в
объект валидатора. Сначала мы покажем, как работают эти функции, а затем дадим
пример с 9Набор данных 0015 samplonomy .
Они могут использоваться интерактивно или, как правило, в
объект валидатора. Сначала мы покажем, как работают эти функции, а затем дадим
пример с 9Набор данных 0015 samplonomy .
is_linear_sequence(c(1,2,3,4))
## [1] TRUE
is_linear_sequence(c(8,6,4,2))
## [1] TRUE
is_linear_sequence( c(2,4,8,16))
## [1] FALSE
Для символьных данных функция способна распознавать определенные форматы для периодов времени.
is_linear_sequence(c("2020Q1","2020Q2","2020Q3","2020Q4")) ## [1] TRUE
См. ?is_linear_sequence для полной спецификации поддерживаемых
форматы даты и времени.
Нет необходимости сортировать данные, чтобы их можно было распознать как линейная последовательность.
is_linear_sequence(c("2020Q4","2020Q2","2020Q3","2020Q1")) ## [1] TRUE
Можно также задать начальную и/или конечную точку последовательности.
is_linear_sequence(c("2020Q4","2020Q2","2020Q3","2020Q1")
, begin = "2020Q2") ## [1] FALSE
Наконец, можно разделить переменную по одному или нескольким другим столбцам и
проверьте, представляет ли каждый блок линейную последовательность.
ряд <- с(1,2,3,4,1,2,3,3)
блоки <- rep(c("a","b"), каждый = 4)
is_linear_sequence(series, by = blocks) ## [1] FALSE
Теперь этот результат не очень полезен, так как теперь неизвестно, какой блок
не является линейным рядом. Здесь на помощь приходит функция in_linear_sequence .
in_linear_sequence(series, by = blocks)
## [1] TRUE TRUE TRUE TRUE FALSE FALSE FALSE FALSE
Есть некоторые тонкости. Отдельный элемент также является линейной последовательностью (длины 1).
is_linear_sequence(5)
## [1] TRUE
Это может привести к сюрпризам в случае блоков длиной 1.
блоков[8] <- "c" data.frame(серия = серия, блоки = блоки)
## блоки серии ## 1 1 а ## 2 2 а ## 3 3 а ## 4 4 а ## 5 1 б ## 6 2 б ## 7 3 б ## 8 3 c
in_linear_sequence(серии, блоки)
## [1] ИСТИНА ИСТИНА ИСТИНА ИСТИНА ИСТИНА ИСТИНА ИСТИНА ИСТИНА ИСТИНА
Теперь у нас есть три линейных ряда, а именно
- Для
"а":1,2,3,4 - Для
"б":1,2,3 - Для
"с":3.
Мы можем обойти это, задав явные границы.
in_linear_sequence(серия, блоки, начало = 1, конец = 4)
## [1] ИСТИНА ИСТИНА ИСТИНА ИСТИНА ИСТИНА ЛОЖЬ ЛОЖЬ ЛОЖЬ ЛОЖЬ ЛОЖЬ
Теперь вернемся к набору данных samplonomy . Мы хотим проверить это для
каждая мера и каждая область, временные ряды являются линейными рядами. С тех пор
являются временными рядами разных частот, нам нужно разделить данные по частоте
также.
правило <- валидатор(
in_linear_sequence (период
, по = список (область, частота, мера))
)
out <- конфронтация (самплономия, правило)
summary(out)[1:7] ## name items pass failed nNA error warning ## 1 V1 1199 1170 29 0 FALSE FALSE
Блоки, в которых записи идут не по порядку, можно найти следующим образом (выводить не напечатано здесь для краткости).
нарушение(выборка, вне)
Проверка выбранных записей показывает, что для Agria ВВП за 2015 г. отсутствует, а для Induston экспорт за 2018Q3 отсутствует, а экспорт
для 2018Q2 встречается дважды (но с разными значениями)
отсутствует, а для Induston экспорт за 2018Q3 отсутствует, а экспорт
для 2018Q2 встречается дважды (но с разными значениями)
SPN и уникальность имени участника-пользователя | Microsoft Learn
- Статья
Применяется к: Windows Server 2022, Windows Server 2019, Windows Server 2016, Windows Server 2012 R2, Windows Server 2012
Автор : Джастин Тернер, старший инженер по расширению поддержки группы Windows
Примечание
Это содержимое написано инженером службы поддержки клиентов Майкрософт и предназначено для опытных администраторов и системных архитекторов, которые ищут более подробные технические описания функций и решений в Windows Server 2012 R2, чем обычно предоставляют темы на TechNet. Тем не менее, он не подвергался такому же редактированию, поэтому некоторые формулировки могут показаться менее отполированными, чем те, которые обычно можно найти на TechNet.
Тем не менее, он не подвергался такому же редактированию, поэтому некоторые формулировки могут показаться менее отполированными, чем те, которые обычно можно найти на TechNet.
Обзор
Контроллеры домена под управлением Windows Server 2012 R2 блокируют создание повторяющихся имен субъектов-служб (SPN) и имен участников-пользователей (UPN). Это включает в себя, если восстановление или реанимация удаленного объекта или переименование объекта приведет к дублированию.
Справочная информация
Обычно повторяющиеся имена участников-служб (SPN) приводят к сбоям проверки подлинности и могут привести к чрезмерной загрузке ЦП LSASS. Не существует встроенного метода, позволяющего заблокировать добавление повторяющегося имени участника-службы или имени участника-пользователя. *
Повторяющиеся значения имени участника-пользователя нарушают синхронизацию между локальным AD и Office 365.
*Setspn.exe обычно используется для создания новых имен участников-служб и функционально был встроен в версию, выпущенную с Windows Server 2008, которая добавляет проверку на наличие дубликатов.
Table SEQ Table \* ARABIC 1: Уникальность UPN и SPN
| Функция | Комментарий |
|---|---|
| Уникальность UPN | Дублирующиеся имена участников-пользователей нарушают синхронизацию локальных учетных записей AD со службами на основе Microsoft Azure AD, такими как Office 365. |
| Уникальность SPN | Kerberos требует SPN для взаимной проверки подлинности. Повторяющиеся имена участников-служб приводят к сбоям проверки подлинности. |
Дополнительные сведения о требованиях к уникальности для имен участников-пользователей и участников-служб см. в разделе Ограничения уникальности.
Симптомы
Коды ошибок 8467 или 8468 или их шестнадцатеричные, символьные или строковые эквиваленты регистрируются в различных экранных диалогах и в событии с идентификатором 2974 в журнале событий служб каталогов. Попытка создать дубликат имени участника-пользователя или имени участника-службы блокируется только при следующих обстоятельствах:
- Запись обрабатывается контроллером домена Windows Server 2012 R2 .

Table SEQ Table \* ARABIC 2: коды ошибок уникальности имени участника-пользователя и участника-службы
| Десятичный | Шестнадцатеричный | Символический | Строка |
|---|---|---|---|
| 8467 | 21С7 | ОШИБКА_DS_SPN_VALUE_NOT_UNIQUE_IN_FOREST | Операция завершилась неудачно, так как значение имени участника-службы, указанное для добавления или изменения, не является уникальным для всего леса. |
| 8648 | 21C8 | ОШИБКА_DS_UPN_VALUE_NOT_UNIQUE_IN_FOREST | Операция завершилась неудачно, так как значение имени участника-пользователя, предоставленное для добавления или изменения, не является уникальным для всего леса. |
Не удается создать нового пользователя, если UPN не уникален
DSA.msc
Выбранное имя пользователя уже используется на этом предприятии. Выберите другое имя для входа и повторите попытку.
Изменить существующую учетную запись:
Указанное имя пользователя уже существует на предприятии. Укажите новый, либо изменив префикс, либо выбрав другой суффикс из списка.
Центр администрирования Active Directory (DSAC.exe)
Попытка создать нового пользователя в центре администрирования Active Directory с уже существующим именем участника-пользователя возвращает следующую ошибку.
Рис. ПОСЛ. 1 Рисунок SEQ Рисунок \* АРАБСКИЙ 2 Идентификатор события 2974 с ошибкой 8648
Событие 2974 перечисляет значение, которое было заблокировано, и список одного или нескольких объектов (до 10), которые уже содержат это значение. На следующем рисунке видно, что значение атрибута UPN [email protected] уже существует для четырех других объектов. Поскольку это новая функция в Windows Server 2012 R2, случайное создание дубликатов имен участников-пользователей и участников-служб в смешанной среде по-прежнему будет происходить, когда контроллеры домена более низкого уровня обрабатывают попытку записи.
Рисунок SEQ Рисунок \* ARABIC 3 Событие 2974, показывающее все объекты, содержащие дубликат UPN PN или SPN 8648 = "Операция завершилась неудачно, так как значение имени участника-пользователя, указанное для добавления/изменения, не является уникальным для всего леса." Setspn.exe имеет встроенное обнаружение дубликатов имени участника-службы, начиная с выпуска Windows Server 2008 при использовании "-S" вариант. Однако вы можете обойти обнаружение повторяющихся SPN, используя параметр "-A" . Создание повторяющегося имени участника-службы блокируется при нацеливании на контроллер домена Windows Server 2012 R2 с использованием SetSPN с параметром -A. Отображаемое сообщение об ошибке такое же, как при использовании параметра -S: «Обнаружен повторяющийся SPN, прерывание операции!» Рис. ПОСЛ. 0002 PowerShell, работающий с Server 2012, ориентированный на Windows Server 2012 R2 DC: DSAC.Exe, работающий на Windows Server 2012, нацеливаясь на Windows Server 2012 R2 DC: Рисунок SEQ Рисунок \* Arabic 5 DSAC Ошибка пользователя. 2012 Р2 DC Рис. ПОСЛ. 002 Событие не регистрируется, когда объект не удается восстановить из-за дублирующегося имени участника-пользователя или участника-службы. Имя участника-пользователя объекта должно быть уникальным, чтобы его можно было восстановить. Определите имя участника-пользователя, существующее для объекта в корзине Идентифицировать все объекты, имеющие одинаковое значение Удалить повторяющиеся UPN Совет Ранее недокументированный параметр /deleted в repadmin.exe используется для включения удаленных объектов в набор результатов. 012 Выберите переключатель Convert to LDAP Тип (userPrincipalName = ConflictingUPN ) Выбрать Применить Если объект необходимо восстановить, необходимо удалить повторяющиеся имена участников-пользователей из других объектов. Только для одного объекта достаточно просто использовать ADSIEdit для удаления дубликатов. Если есть несколько объектов с дубликатами, лучше использовать Windows PowerShell. Чтобы обнулить атрибут UserPrincipalName с помощью Windows PowerShell: Примечание Атрибут userPrincipalName является однозначным атрибутом, поэтому эта процедура удалит только повторяющееся имя участника-пользователя. Рисунок SEQ Рисунок \* ARABIC 8 Сообщение об ошибке, отображаемое в ADSIEdit, когда добавление повторяющегося имени участника-службы заблокировано0012 идентификатор события 2974 . Рис. ПОСЛЕД. Рис. \* ARABIC 9 Зарегистрирована ошибка при блокировании создания повторяющегося имени участника-службы При повторной анимации удаленных объектов существующие значения имени участника-службы или имени участника-пользователя проверяются на уникальность. Если дубликат найден, запрос не выполняется. При изменении определенных атрибутов, таких как имя хоста DNS, имя учетной записи SAM и т. д., имена участников-служб обновляются соответствующим образом. При этом устаревшие имена участников-служб удаляются, а новые имена участников-служб создаются и добавляются в базу данных. Требуемые модификации атрибутов, для которых активируется этот путь: ATT_DNS_HOST_NAME ATT_MS_DS_ADDITIONAL_DNS_HOST_NAME ATT_SAM_ACCOUNT_NAME ATT_MS_DS_ADDITIONAL_SAM_ACCOUNT_NAME ATT_SERVER_REFERENCE_BL ATT_USER_ACCOUNT_CONTROL Если какое-либо из новых значений имени участника-службы является дубликатом, модификация завершается неудачей. Это первый из нескольких " Try This " в модуле. Для этого модуля нет отдельного лабораторного руководства. Задания Try This представляют собой задания в свободной форме, которые позволяют изучить материал урока в лабораторной среде. У вас есть возможность следуя подсказке или отклоняясь от сценария, и придумать собственное задание Примечание Эксперимент с уникальностью имени участника-службы и имени участника-пользователя. Следуйте этим инструкциям или заполните свои собственные. Создание новых пользователей с UPN Создание учетных записей с именами участников-служб Либо создайте нового пользователя с уже определенным ранее именем участника-пользователя, либо измените имя участника-пользователя существующей учетной записи. Сделайте то же самое для имени участника-службы в другой учетной записи Заполнить существующую учетную запись пользователя уже используемым именем участника-пользователя Заполните существующую учетную запись уже используемым именем участника-службы Обратите внимание на ошибки Дополнительно Уточните у классного преподавателя, можно ли включить Корзину AD в Центре администрирования Active Directory. SetSPN:
ADSIEDIT:
Операция не выполнена.
.png) Код ошибки: 0x21c8
Операция завершилась неудачно, так как значение имени участника-пользователя, предоставленное для добавления или изменения, не является уникальным для всего леса.
000021C8: AtrErr: DSID-03200BBA, #1: 0: 000021C8: DSID-03200BBA, проблема 1005 (CONSTRAINT_ATT_TYPE), данные 0, Att
Код ошибки: 0x21c8
Операция завершилась неудачно, так как значение имени участника-пользователя, предоставленное для добавления или изменения, не является уникальным для всего леса.
000021C8: AtrErr: DSID-03200BBA, #1: 0: 000021C8: DSID-03200BBA, проблема 1005 (CONSTRAINT_ATT_TYPE), данные 0, Att (имя-пользователя)
Определение конфликтующего имени участника-пользователя на удаленном объекте с помощью repadmin.
 exe
exe Repadmin /showattr DCName "DN контейнера удаленных объектов" /subtree /filter:"(msDS-LastKnownRDN=
repadmin /showattr DCName "CN = Deleted Objects, DC = blue, DC = contoso, DC = com" /subtree /filter:"(msDS-LastKnownRDN=Dianne Hunt2)" /deleted /atts:userprincipalname
C:\>repadmin /showattr winbluedc1 "cn=удаленные объекты,dc=blue,dc=contoso,dc=com" /subtree /filter:"(msds-lastknownrdn=Dianne Hunt2)" /deleted /atts:userprincipalname
DN: CN=Dianne Hunt2\0ADEL:dd3ab8a4-3005-4f2f-814f-d6fc54a1a1c0,CN=удаленный объект
s,DC=синий,DC=contoso,DC=com
1> userPrincipalName: [email protected]
Чтобы идентифицировать все объекты с одинаковым именем участника-пользователя: с помощью Repadmin.exe
repadmin /showattr WinBlueDC1 "DC=blue,DC=contoso,DC=com" /subtree/filter:"([email protected] )" /удалено /atts:DN
C:\>repadmin /showattr winbluedc1 "dc=blue,dc=contoso,dc=com" /subtree/filter:"(userPrincipalName=dhunt@blue.
 contoso.com)" /deleted /atts:DN
DN: CN = администратор, CN = пользователи, DC = blue, DC = contoso, DC = com
DN: CN=xouser1,CN=Users,DC=blue,DC=contoso,DC=com
DN: CN=xouser10,CN=Users,DC=blue,DC=contoso,DC=com
DN: CN=xouser100,CN=Users,DC=blue,DC=contoso,DC=com
DN: CN = Дайан Хант, OU = Marketing, DC = blue, DC = contoso, DC = com
DN: CN=Dianne Hunt2\0ADEL:dd3ab8a4-3005-4f2f-814f-d6fc54a1a1c0,CN=Deleted Objects,DC=blue,DC=contoso,DC=com
contoso.com)" /deleted /atts:DN
DN: CN = администратор, CN = пользователи, DC = blue, DC = contoso, DC = com
DN: CN=xouser1,CN=Users,DC=blue,DC=contoso,DC=com
DN: CN=xouser10,CN=Users,DC=blue,DC=contoso,DC=com
DN: CN=xouser100,CN=Users,DC=blue,DC=contoso,DC=com
DN: CN = Дайан Хант, OU = Marketing, DC = blue, DC = contoso, DC = com
DN: CN=Dianne Hunt2\0ADEL:dd3ab8a4-3005-4f2f-814f-d6fc54a1a1c0,CN=Deleted Objects,DC=blue,DC=contoso,DC=com
Использование Windows PowerShell
Get-ADObject -LdapFilter "(userPrincipalName=dhunt@blue.
 contoso.com)" -IncludeDeletedObjects -SearchBase "DC=blue,DC=Contoso,DC=com" -SearchScope Subtree -Server winbluedc1 .blue.contoso.com
contoso.com)" -IncludeDeletedObjects -SearchBase "DC=blue,DC=Contoso,DC=com" -SearchScope Subtree -Server winbluedc1 .blue.contoso.com
Дублированное имя участника-службы
Операция не выполнена.
 Код ошибки: 0x21c7
Операция не удалась
Предоставленное значение атрибута не является уникальным в лесу или разделе. Атрибут:
servicePrincipalName Значение =
Код ошибки: 0x21c7
Операция не удалась
Предоставленное значение атрибута не является уникальным в лесу или разделе. Атрибут:
servicePrincipalName Значение = Рабочий процесс
В приведенном выше списке важными атрибутами являются ATT_DNS_HOST_NAME (имя компьютера) и ATT_SAM_ACCOUNT_NAME (имя учетной записи SAM). Попробуйте это: Изучение уникальности имени участника-службы и имени участника-пользователя